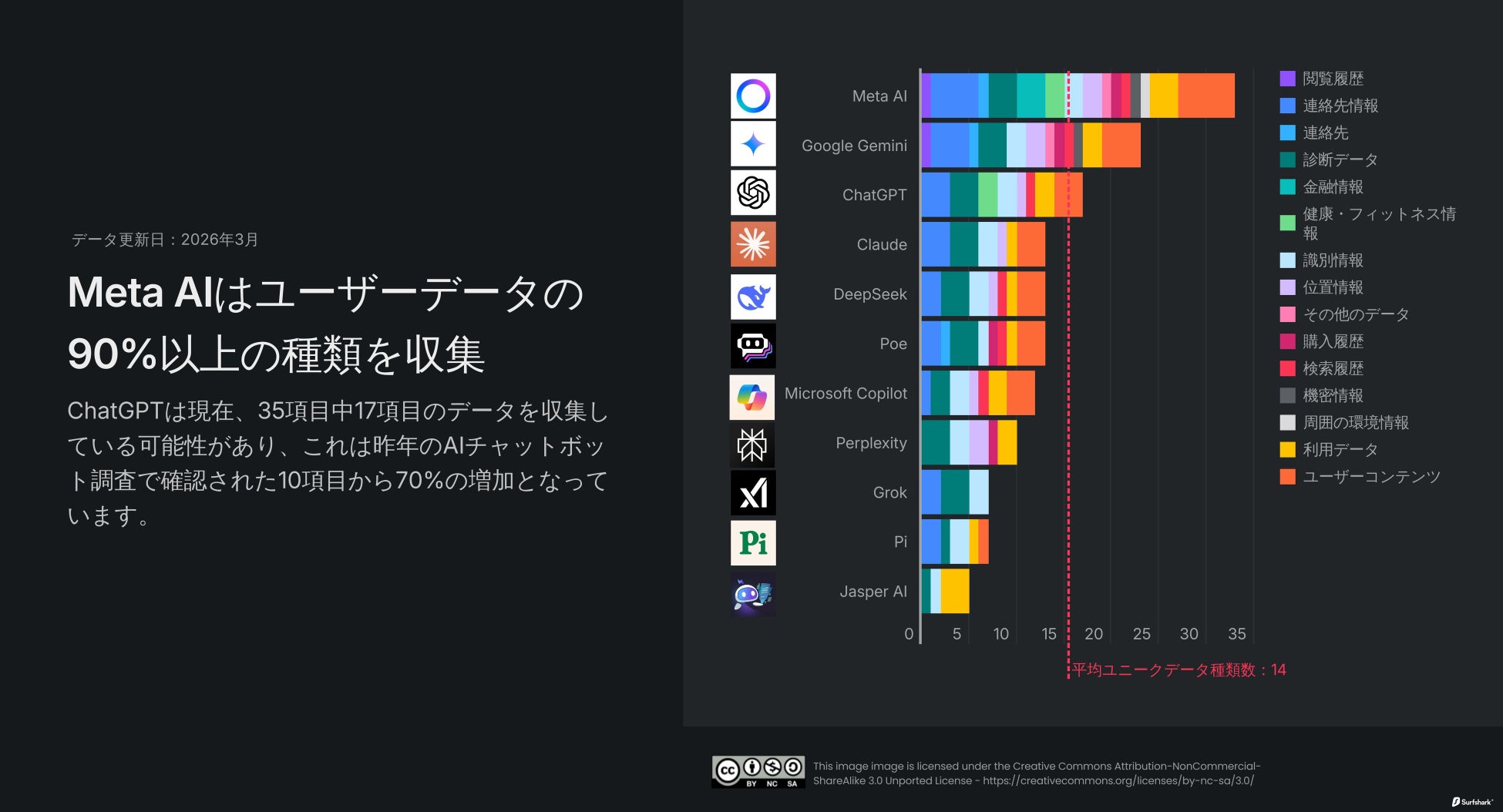
根據 Surfshark 的最新分析,受歡迎的 AI(人工智能)聊天機器人應用程式正在收集各種資訊,包括聯絡人資訊、搜尋和瀏覽記錄以及其他用戶內容。此外,收集用戶位置資訊的 AI 聊天機器人比例已從去年的 40% 增加到今年的 70%。
本次分析中的所有 AI 聊天機器人應用程式都會收集某種形式的使用者資料,平均收集 35 個資料點中的 14 個。
Surfshark 的首席安全官(CSO)Thomas Stamulis(以下簡稱「他」)表示:
「聊天機器人對用戶數據的收集越來越積極。我們的研究顯示,70% 的熱門 AI 應用程式會收集位置資訊,這比去年的 40% 有顯著增長。這種數據收集擴大趨勢也體現在 ChatGPT 上,它最近將收集範圍擴大了 70%,納入了健康與健身資訊、搜尋記錄和語音數據等。」
「與傳統搜尋引擎不同,這些 AI 會處理稅務文件和醫療記錄等極度敏感的數據。這些資訊可能會與大型第三方網路共享,用於定向廣告。」
「為了保護您的隱私,重要的是要意識到所有提示都可能被視為可能公開的資訊。請檢查您的設定,刪除您的聊天記錄,切勿輸入您不希望公開的資訊。」
AI 聊天機器人中,Meta AI 收集的數據最多,其次是 Gemini 和 ChatGPT
在分析的應用程式中,Meta AI 仍然收集最多的用戶數據,佔 35 個數據點中的 33 個,約佔 95%。Meta AI 是唯一收集金融資訊類別數據的應用程式。此外,Meta AI 和 Google Gemini 會收集敏感資訊,包括種族/民族、性取向、懷孕/生育、殘疾、宗教/信仰、工會會員資格、政治觀點、遺傳資訊和生物特徵數據。
Google Gemini 收集 35 個數據點中的 23 個。它獲取廣泛的數據,包括姓名、電子郵件地址和電話號碼等聯絡人資訊、用戶內容、聯絡人(裝置通訊錄資訊)、搜尋記錄、瀏覽記錄和精確位置資訊。對於重視隱私和安全的用戶來說,如此廣泛的數據收集可能顯得過度且有些侵入。
根據 Apple 的 App Store 資訊,開發者表示 ChatGPT 目前可能會收集 35 個數據點中的 17 個。與去年的 AI 聊天機器人調查相比,這是一個顯著的增長。
常見問題
What is the main finding of the Surfshark analysis regarding AI chatbots?
The Surfshark analysis reveals that popular AI chatbot apps are collecting a wide range of user data, including sensitive information, and that the percentage of these apps collecting location data has significantly increased from 40% last year to 70% this year.
Which AI chatbots collect the most user data according to the analysis?
Meta AI collects the most user data (95%), followed by Google Gemini (23 out of 35 data points), and then ChatGPT (17 out of 35 data points).
What types of sensitive data are AI chatbots collecting?
Sensitive data collected can include race/ethnicity, sexual orientation, pregnancy/childbirth, disability, religion/beliefs, trade union membership, political opinions, genetic information, biometric data, health and fitness information, search history, and voice data.
Why is the collection of this data a concern?
The collection of such extensive and sensitive data raises privacy concerns, as it could be shared with third-party networks for targeted advertising or other purposes, and unlike traditional search engines, these AIs handle highly confidential information like tax and medical records.
What advice is given to users to protect their privacy?
Users are advised to treat all prompts as potentially public information, review their app settings, delete chat history, and avoid inputting any information they would not want to be made public.